Overview¶
This notebook describes how to construct GRN models in CellOracle. Please read our paper first to know about the CellOracle’s GRN modeling algorithm.
Last update: 4/13/2022, Kenji Kamimoto
Notebook file¶
Notebook file is available on CellOracle’s GitHub page. https://github.com/morris-lab/CellOracle/blob/master/docs/notebooks/04_Network_analysis/Network_analysis_with_Paul_etal_2015_data.ipynb
Data¶
CellOracle uses two types of input data during the GRN model construction.
Input data 1: scRNA-seq data. Please look at the previous section to learn about the scRNA-seq data preprocessing. https://morris-lab.github.io/CellOracle.documentation/tutorials/scrnaprocess.html
Input data 2: Base-GRN. The base GRN represents the TF-target gene connections. The data structure is a binary 2D matrix or linklist. Please look at our paper to know the concept of base GRN.
CellOracle typically uses a base GRN constructed from scATAC-seq data. If you would like to create a custom base GRN using your scATAC-seq data, please refer to the following notebook. https://morris-lab.github.io/CellOracle.documentation/tutorials/base_grn.html
- If you do not have any sample-specific scATAC-seq data that correspond to the same/similar cell type of the scRNA-seq data, please use pre-built base GRN.
We provide multiple options for pre-built base GRN. For analyses in mice, we recommend using a base GRN built from the mouse sciATAC-seq Atlas dataset. It includes various tissues and various cell types. Another option is using base GRN constructed from promoter database. We provide promoter base GRNs for ten species.
What you can do¶
After constructing the CellOracle GRN models, you can do two analyses.
in silico TF perturbation analysis. CellOracle uses the GRN models to simulate cell identity shifts in response to TF perturbation. For this analysis, you must first construct your GRN models in this notebook.
Network analysis. You can analyze the GRN models using graph theory. We provide several functions.
CellOracle construct cluster-wise GRN models. You can compare the GRN model structure between clusters, which allows you to investigate the cell type-specific GRN configurations and explore structual changes as GRNs are rewired along the cell differentiation trajectory.
You can also export the network models and analyze the GRN models using external packages or softwares.
Custom data classes / objects¶
In this notebook, CellOracle uses two custom classes, Oracle and Links.
Oracleis the main class in the CellOracle package. It is responsible for almost all the GRN model construction and TF perturbation simulation.Oracledoes the following calculations sequentially.
Import scRNA-sequence data. Please refer to the data preparation notebooks to learn about data preparation procedures.
Import base GRN data.
scRNA-seq data processing.
GRN model construction.
in silico petrurbation. We will describe how to do this in the following notebook.
Linksis a class to store GRN data. It also conteins many functions for network analysis and visualization.
0. Import libraries¶
[1]:
# 0. Import
import os
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scanpy as sc
import seaborn as sns
[5]:
import celloracle as co
co.__version__
[5]:
'0.10.14'
[6]:
# visualization settings
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
plt.rcParams['figure.figsize'] = [6, 4.5]
plt.rcParams["savefig.dpi"] = 300
[7]:
save_folder = "figures"
os.makedirs(save_folder, exist_ok=True)
1. Load data¶
Please refer to the previous notebook to learn about scRNA-seq data processing. https://morris-lab.github.io/CellOracle.documentation/tutorials/scrnaprocess.html
The scRNA-seq data must be in the anndata format.
This CellOracle tutorial notebook assumes the user has basic knowledge and experience with scRNA-seq analysis using Scanpy and Anndata. This notebook is not intended to be an introduction to Scanpy or Anndata. If you are not familiar with them, please learn them using the documentation and tutorials for Scanpy (https://scanpy.readthedocs.io/en/stable/) and annata (https://anndata.readthedocs.io/en/stable/).
[6]:
# Load data.
# Here, we will use a hematopoiesis data by Paul 2015.
# You can load preprocessed data using a celloracle function as follows.
adata = co.data.load_Paul2015_data()
adata
# Attention: Replace the data path below when using your data.
# adata = sc.read_h5ad("DATAPATH")
[6]:
AnnData object with n_obs × n_vars = 2671 × 1999
obs: 'paul15_clusters', 'n_counts_all', 'n_counts', 'louvain', 'cell_type', 'louvain_annot', 'dpt_pseudotime'
var: 'n_counts'
uns: 'cell_type_colors', 'diffmap_evals', 'draw_graph', 'iroot', 'louvain', 'louvain_annot_colors', 'louvain_colors', 'louvain_sizes', 'neighbors', 'paga', 'paul15_clusters_colors', 'pca'
obsm: 'X_diffmap', 'X_draw_graph_fa', 'X_pca'
varm: 'PCs'
layers: 'raw_count'
obsp: 'connectivities', 'distances'
If your scRNA-seq data includes more than 20-30K cells, we recommend downsampling your data. If you do not, please note the perturbation simulations may require large amounts of memory in the next notebook.
Also, please pay attention to the number of genes. If you are following the instruction from the previous tutorial notebook, the scRNA-seq data should include only top 2~3K variable genes. If you have more than 3K genes, it may cause issues downstream.
[7]:
print(f"Cell number is :{adata.shape[0]}")
print(f"Gene number is :{adata.shape[1]}")
Cell number is :2671
Gene number is :1999
[8]:
# Random downsampling into 30K cells if the anndata object include more than 30 K cells.
n_cells_downsample = 30000
if adata.shape[0] > n_cells_downsample:
# Let's dowmsample into 30K cells
sc.pp.subsample(adata, n_obs=n_cells_downsample, random_state=123)
[9]:
print(f"Cell number is :{adata.shape[0]}")
Cell number is :2671
To infer cluster-specific GRNs, CellOracle requires a base GRN. - There are several ways to make a base GRN. We can typically generate base GRN from scATAC-seq data or bulk ATAC-seq data. Please refer to the first step of the tutorial to learn more about this process. https://morris-lab.github.io/CellOracle.documentation/tutorials/base_grn.html
If you do not have your scATAC-seq data, you can use one of the built-in base GRNs options below.
Base GRNs made from mouse sci-ATAC-seq atlas : The built-in base GRN was made from various tissue/cell-types found in the atlas (http://atlas.gs.washington.edu/mouse-atac/). We recommend using this for mouse scRNA-seq data. Please load this data as follows.
base_GRN = co.data.load_mouse_scATAC_atlas_base_GRN()
Promoter base GRN: We also provide base GRN made from promoter DNA-sequences for ten species. You can load this data as follows.
e.g. for Human:
base_GRN = co.data.load_human_promoter_base_GRN()
[10]:
# Load TF info which was made from mouse cell atlas dataset.
base_GRN = co.data.load_mouse_scATAC_atlas_base_GRN()
# Check data
base_GRN.head()
[10]:
| peak_id | gene_short_name | 9430076c15rik | Ac002126.6 | Ac012531.1 | Ac226150.2 | Afp | Ahr | Ahrr | Aire | ... | Znf784 | Znf8 | Znf816 | Znf85 | Zscan10 | Zscan16 | Zscan22 | Zscan26 | Zscan31 | Zscan4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr10_100050979_100052296 | 4930430F08Rik | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | chr10_101006922_101007748 | SNORA17 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | chr10_101144061_101145000 | Mgat4c | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | chr10_10148873_10149183 | 9130014G24Rik | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | chr10_10149425_10149815 | 9130014G24Rik | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 1095 columns
2. Make Oracle object¶
We will use an Oracle object during the data preprocessing and GRN inference steps. Using its internal functions, the Oracle object computes and stores all of the necessary information for these calculations. To begin, we will instantiate a new Oracle object and input our gene expression data (anndata) and TF info (base GRN).
[11]:
# Instantiate Oracle object
oracle = co.Oracle()
For the CellOracle analysis, your anndata should include (1) gene expression counts, (2) clustering information, and (3) trajectory (dimensional reduction embedding) data. Please refer to a previous notebook for more information on anndata preprocessing.
When you load the scRNA-seq data, please enter the name of the clustering data and the name of the dimensionality reduction. - The clustering data should be to be stored in the obs the attribute of anndata. > You can check it using the following command. > > adata.obs.columns
Dimensional reduction data is stored in the
obsmthe attribute of anndata. > You can check it with the following command. > >adata.obsm.keys()
[12]:
# Check data in anndata
print("Metadata columns :", list(adata.obs.columns))
print("Dimensional reduction: ", list(adata.obsm.keys()))
metadata columns : ['paul15_clusters', 'n_counts_all', 'n_counts', 'louvain', 'cell_type', 'louvain_annot', 'dpt_pseudotime']
dimensional reduction: ['X_diffmap', 'X_draw_graph_fa', 'X_pca']
[13]:
# In this notebook, we use the unscaled mRNA count for the nput of Oracle object.
adata.X = adata.layers["raw_count"].copy()
# Instantiate Oracle object.
oracle.import_anndata_as_raw_count(adata=adata,
cluster_column_name="louvain_annot",
embedding_name="X_draw_graph_fa")
[14]:
# You can load TF info dataframe with the following code.
oracle.import_TF_data(TF_info_matrix=base_GRN)
# Alternatively, if you saved the informmation as a dictionary, you can use the code below.
# oracle.import_TF_data(TFdict=TFinfo_dictionary)
We can add additional TF-target gene pairs manually.
For example, if there is a study or database that includes specific TF-target pairs, you can include this information using a python dictionary.
2.3.1. Make dictionary¶
Here, we will introduce how to manually add TF-target gene pair data.
As an example, we will use TF binding data from supplemental table 4 in the Paul et al., (2015) paper. (http://doi.org/10.1016/j.cell.2015.11.013).
You can download this file by running the command below. Or download it manually here. https://raw.githubusercontent.com/morris-lab/CellOracle/master/docs/demo_data/TF_data_in_Paul15.csv
In order to import the TF data into the Oracle object, we need to convert it into a python dictionary. The dictionary keys will be the target gene, and dictionary values will be a list of regulatory candidate TFs.
[15]:
# Download file.
!wget https://raw.githubusercontent.com/morris-lab/CellOracle/master/docs/demo_data/TF_data_in_Paul15.csv
# If you are using macOS, please try the following command.
#!curl -O https://raw.githubusercontent.com/morris-lab/CellOracle/master/docs/demo_data/TF_data_in_Paul15.csv
--2022-05-07 18:28:33-- https://raw.githubusercontent.com/morris-lab/CellOracle/master/docs/demo_data/TF_data_in_Paul15.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.108.133, 185.199.111.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1771 (1.7K) [text/plain]
Saving to: ‘TF_data_in_Paul15.csv.2’
TF_data_in_Paul15.c 100%[===================>] 1.73K --.-KB/s in 0s
2022-05-07 18:28:33 (38.3 MB/s) - ‘TF_data_in_Paul15.csv.2’ saved [1771/1771]
[16]:
# Load the TF and target gene information from Paul et al. (2015).
Paul_15_data = pd.read_csv("TF_data_in_Paul15.csv")
Paul_15_data
[16]:
| TF | Target_genes | |
|---|---|---|
| 0 | Cebpa | Abcb1b, Acot1, C3, Cnpy3, Dhrs7, Dtx4, Edem2, ... |
| 1 | Irf8 | Abcd1, Aif1, BC017643, Cbl, Ccdc109b, Ccl6, d6... |
| 2 | Irf8 | 1100001G20Rik, 4732418C07Rik, 9230105E10Rik, A... |
| 3 | Klf1 | 2010011I20Rik, 5730469M10Rik, Acsl6, Add2, Ank... |
| 4 | Spi1 | 0910001L09Rik, 2310014H01Rik, 4632428N05Rik, A... |
[17]:
# Make dictionary: dictionary key is TF and dictionary value is list of target genes.
TF_to_TG_dictionary = {}
for TF, TGs in zip(Paul_15_data.TF, Paul_15_data.Target_genes):
# convert target gene to list
TG_list = TGs.replace(" ", "").split(",")
# store target gene list in a dictionary
TF_to_TG_dictionary[TF] = TG_list
# We invert the dictionary above using a utility function in celloracle.
TG_to_TF_dictionary = co.utility.inverse_dictionary(TF_to_TG_dictionary)
2.3.2. Add TF information dictionary into the oracle object¶
[18]:
# Add TF information
oracle.addTFinfo_dictionary(TG_to_TF_dictionary)
3. KNN imputation¶
CellOracle uses the same strategy as velocyto for visualizing cell transitions. This process requires KNN imputation in advance.
For the KNN imputation, we first need to calculate and select PCs.
[19]:
# Perform PCA
oracle.perform_PCA()
# Select important PCs
plt.plot(np.cumsum(oracle.pca.explained_variance_ratio_)[:100])
n_comps = np.where(np.diff(np.diff(np.cumsum(oracle.pca.explained_variance_ratio_))>0.002))[0][0]
plt.axvline(n_comps, c="k")
plt.show()
print(n_comps)
n_comps = min(n_comps, 50)
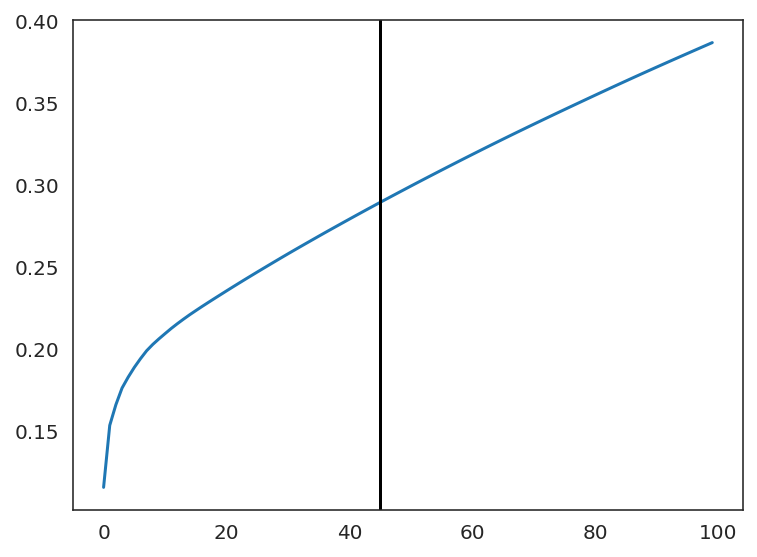
Estimate the optimal number of nearest neighbors for KNN imputation.
[20]:
n_cell = oracle.adata.shape[0]
print(f"cell number is :{n_cell}")
cell number is :2671
[21]:
k = int(0.025*n_cell)
print(f"Auto-selected k is :{k}")
Auto-selected k is :66
[22]:
oracle.knn_imputation(n_pca_dims=n_comps, k=k, balanced=True, b_sight=k*8,
b_maxl=k*4, n_jobs=4)
4. Save and Load.¶
You can save your Oracle object using Oracle.to_hdf5(FILE_NAME.celloracle.oracle).
Pleasae use co.load_hdf5(FILE_NAME.celloracle.oracle) to load the saved file.
[23]:
# Save oracle object.
oracle.to_hdf5("Paul_15_data.celloracle.oracle")
[24]:
# Load file.
oracle = co.load_hdf5("Paul_15_data.celloracle.oracle")
5. GRN calculation¶
The next step constructs a cluster-specific GRN for all clusters.
You can calculate GRNs with the
get_linksfunction, and it will return the results as aLinksobject. TheLinksobject stores the inferred GRNs and the corresponding metadata. Most network structure analysis is performed with theLinksobject.A GRN will be calculated for each cluster/sub-group. In the example below, we construct GRN for each unit of the “louvain_annot” clustering.
[25]:
# Check clustering data
sc.pl.draw_graph(oracle.adata, color="louvain_annot")
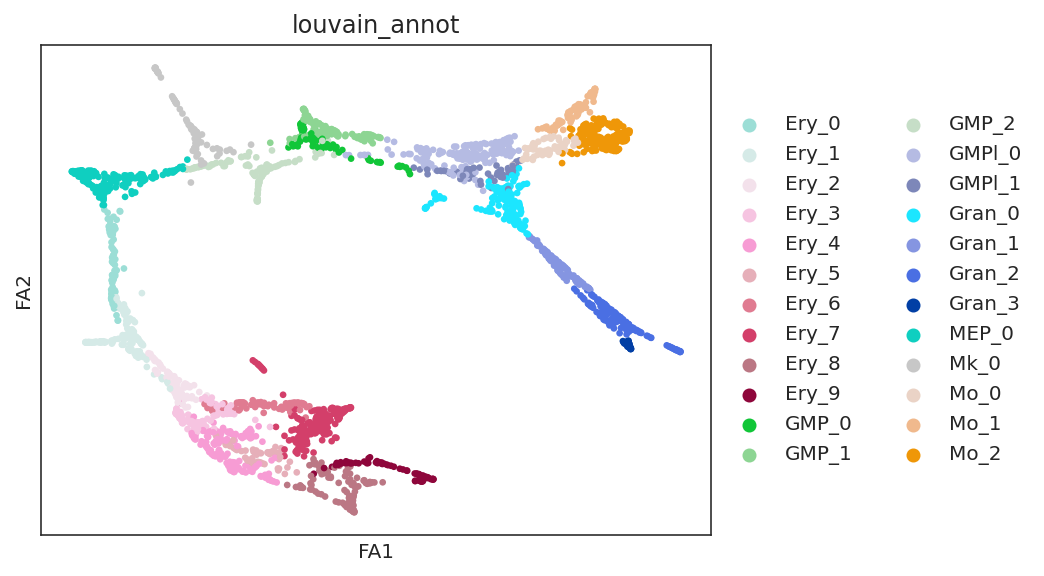
[26]:
%%time
# Calculate GRN for each population in "louvain_annot" clustering unit.
# This step may take some time.(~30 minutes)
links = oracle.get_links(cluster_name_for_GRN_unit="louvain_annot", alpha=10,
verbose_level=10)
Although CellOracle has many functions for network analysis, you can export and analyze GRNs using another software if you chose. The raw GRN data is stored as a dictionary of dataframe in the links_dict attribute.
For example, you can get the GRN for the “Ery_0” cluster with the following commands.
[27]:
links.links_dict.keys()
[27]:
dict_keys(['Ery_0', 'Ery_1', 'Ery_2', 'Ery_3', 'Ery_4', 'Ery_5', 'Ery_6', 'Ery_7', 'Ery_8', 'Ery_9', 'GMP_0', 'GMP_1', 'GMP_2', 'GMPl_0', 'GMPl_1', 'Gran_0', 'Gran_1', 'Gran_2', 'Gran_3', 'MEP_0', 'Mk_0', 'Mo_0', 'Mo_1', 'Mo_2'])
[28]:
links.links_dict["Ery_0"]
[28]:
| source | target | coef_mean | coef_abs | p | -logp | |
|---|---|---|---|---|---|---|
| 0 | Elf1 | 0610007L01Rik | 0.003746 | 0.003746 | 1.440512e-03 | 2.841483 |
| 1 | Mef2c | 0610007L01Rik | -0.007328 | 0.007328 | 1.365241e-04 | 3.864791 |
| 2 | Chd2 | 0610007L01Rik | -0.010170 | 0.010170 | 4.160059e-06 | 5.380900 |
| 3 | Irf7 | 0610007L01Rik | -0.009342 | 0.009342 | 2.462105e-06 | 5.608693 |
| 4 | Stat3 | 0610007L01Rik | -0.008464 | 0.008464 | 1.636075e-04 | 3.786197 |
| ... | ... | ... | ... | ... | ... | ... |
| 74932 | Nfkb1 | Zyx | 0.015513 | 0.015513 | 6.787753e-06 | 5.168274 |
| 74933 | Zbtb4 | Zyx | 0.000247 | 0.000247 | 8.890848e-01 | 0.051057 |
| 74934 | Klf4 | Zyx | -0.005566 | 0.005566 | 9.731835e-08 | 7.011805 |
| 74935 | Nfia | Zyx | -0.026013 | 0.026013 | 2.981702e-10 | 9.525536 |
| 74936 | Rel | Zyx | -0.002867 | 0.002867 | 1.196048e-01 | 0.922251 |
74937 rows × 6 columns
You can export the file as follows.
[29]:
# Set cluster name
cluster = "Ery_0"
# Save as csv
#links.links_dict[cluster].to_csv(f"raw_GRN_for_{cluster}.csv")
The links object stores color information in the palette attribute. This information is used when visualizing the clusters.
The sample will be visualized in that order. Here we can change both the cluster colors and order.
[30]:
# Show the contents of pallete
links.palette
[30]:
| palette | |
|---|---|
| Ery_0 | #9CDED6 |
| Ery_1 | #D5EAE7 |
| Ery_2 | #F3E1EB |
| Ery_3 | #F6C4E1 |
| Ery_4 | #F79CD4 |
| Ery_5 | #E6AFB9 |
| Ery_6 | #E07B91 |
| Ery_7 | #D33F6A |
| Ery_8 | #BB7784 |
| Ery_9 | #8E063B |
| GMP_0 | #11C638 |
| GMP_1 | #8DD593 |
| GMP_2 | #C6DEC7 |
| GMPl_0 | #B5BBE3 |
| GMPl_1 | #7D87B9 |
| Gran_0 | #1CE6FF |
| Gran_1 | #8595E1 |
| Gran_2 | #4A6FE3 |
| Gran_3 | #023FA5 |
| MEP_0 | #0FCFC0 |
| Mk_0 | #C7C7C7 |
| Mo_0 | #EAD3C6 |
| Mo_1 | #F0B98D |
| Mo_2 | #EF9708 |
[31]:
# Change the order of pallete
order = ['MEP_0', 'Mk_0', 'Ery_0',
'Ery_1', 'Ery_2', 'Ery_3', 'Ery_4', 'Ery_5', 'Ery_6', 'Ery_7', 'Ery_8', 'Ery_9',
'GMP_0', 'GMP_1', 'GMP_2', 'GMPl_0', 'GMPl_1',
'Mo_0', 'Mo_1', 'Mo_2',
'Gran_0', 'Gran_1', 'Gran_2', 'Gran_3']
links.palette = links.palette.loc[order]
links.palette
[31]:
| palette | |
|---|---|
| MEP_0 | #0FCFC0 |
| Mk_0 | #C7C7C7 |
| Ery_0 | #9CDED6 |
| Ery_1 | #D5EAE7 |
| Ery_2 | #F3E1EB |
| Ery_3 | #F6C4E1 |
| Ery_4 | #F79CD4 |
| Ery_5 | #E6AFB9 |
| Ery_6 | #E07B91 |
| Ery_7 | #D33F6A |
| Ery_8 | #BB7784 |
| Ery_9 | #8E063B |
| GMP_0 | #11C638 |
| GMP_1 | #8DD593 |
| GMP_2 | #C6DEC7 |
| GMPl_0 | #B5BBE3 |
| GMPl_1 | #7D87B9 |
| Mo_0 | #EAD3C6 |
| Mo_1 | #F0B98D |
| Mo_2 | #EF9708 |
| Gran_0 | #1CE6FF |
| Gran_1 | #8595E1 |
| Gran_2 | #4A6FE3 |
| Gran_3 | #023FA5 |
[32]:
# Save Links object.
links.to_hdf5(file_path="links.celloracle.links")
6. Network preprocessing¶
Using the base GRN, CellOracle constructs the GRN models as a lits of directed edges between a TF and its target genes. We need to remove the weak edges or insignificant edges before doing network structure analysis.
We filter the network edges as follows.
Remove uncertain network edges based on the p-value.
Remove weak network edge. In this tutorial, we keep the top 2000 edges ranked by edge strength.
The raw network data is stored in the links_dict attribute, while the filtered network data is stored in the filtered_links attribute.
[33]:
links.filter_links(p=0.001, weight="coef_abs", threshold_number=2000)
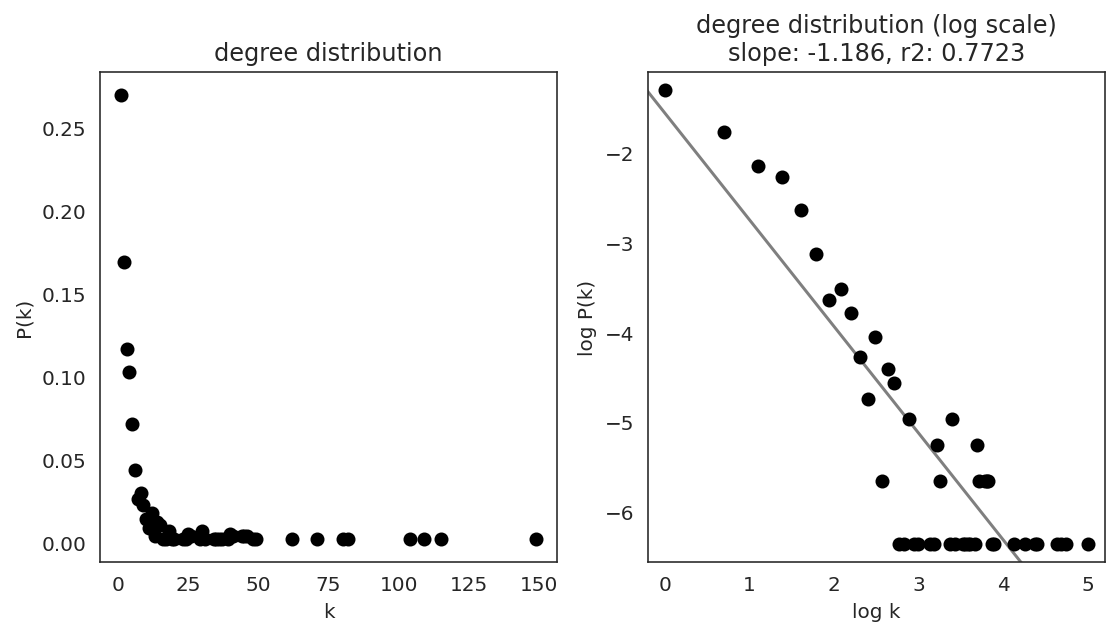
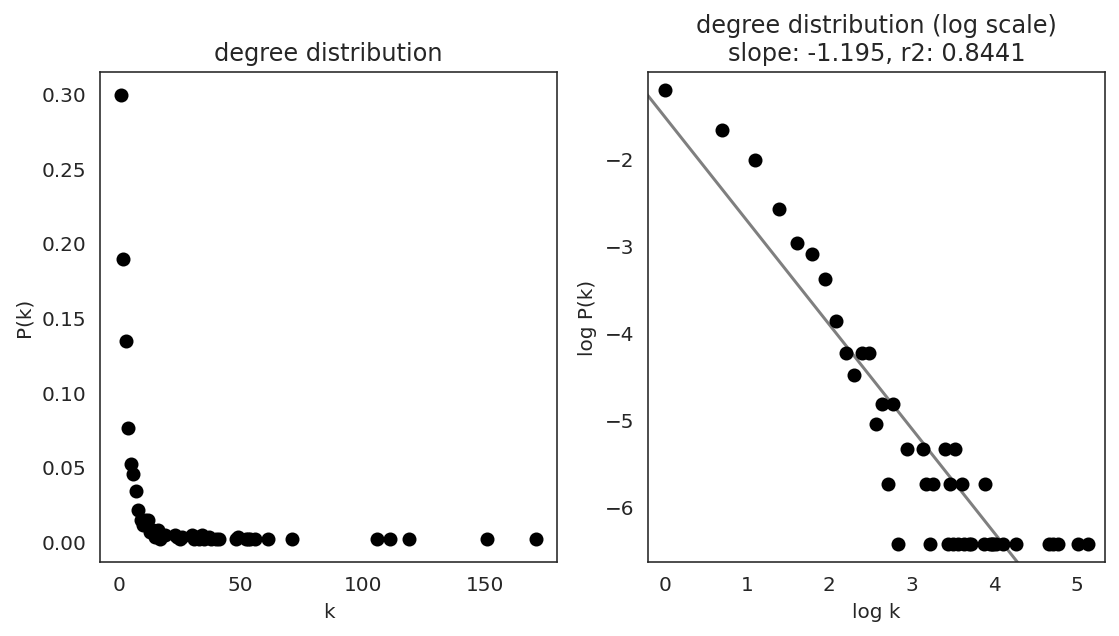
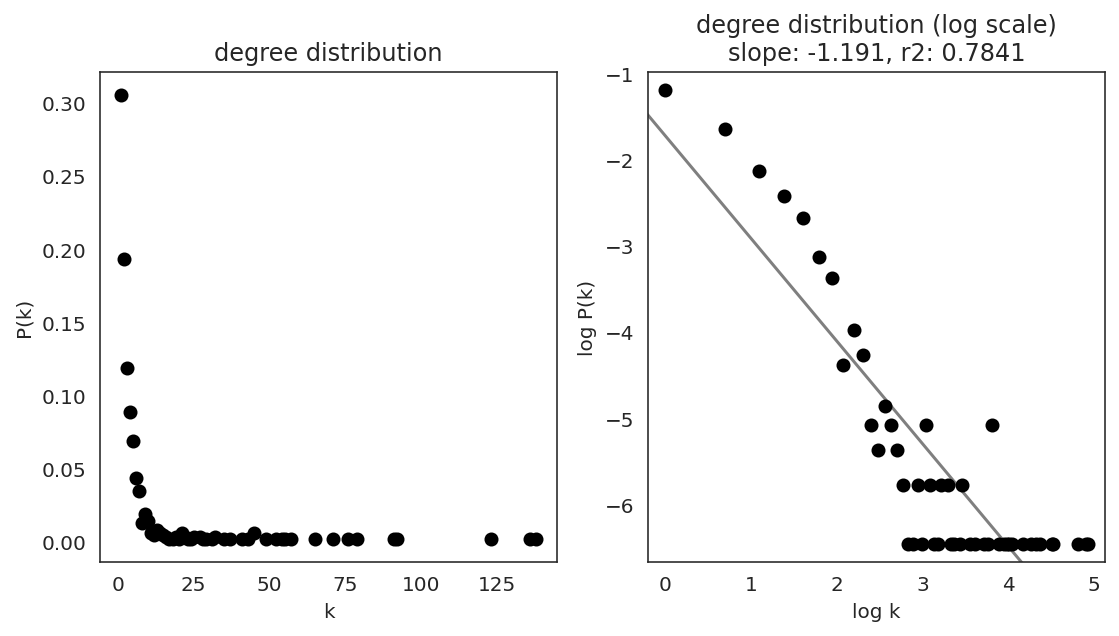
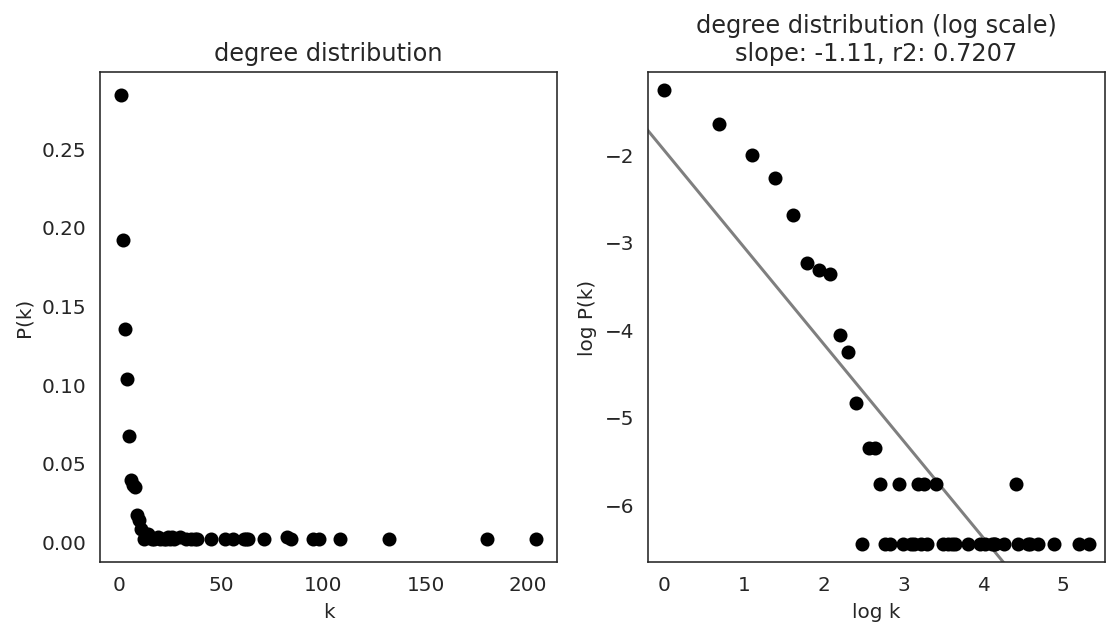
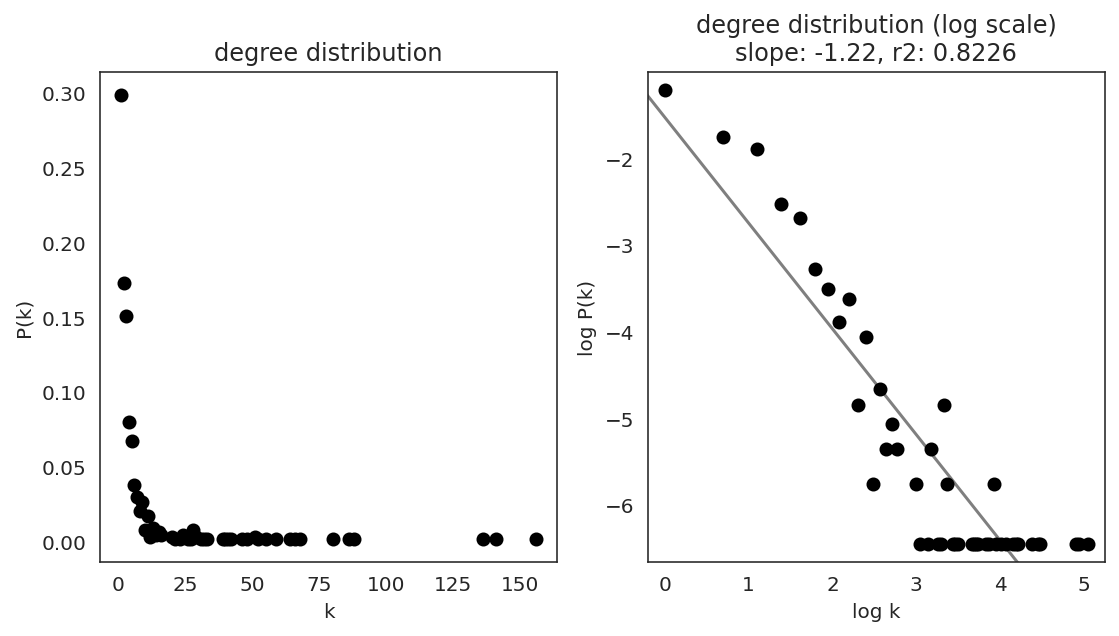
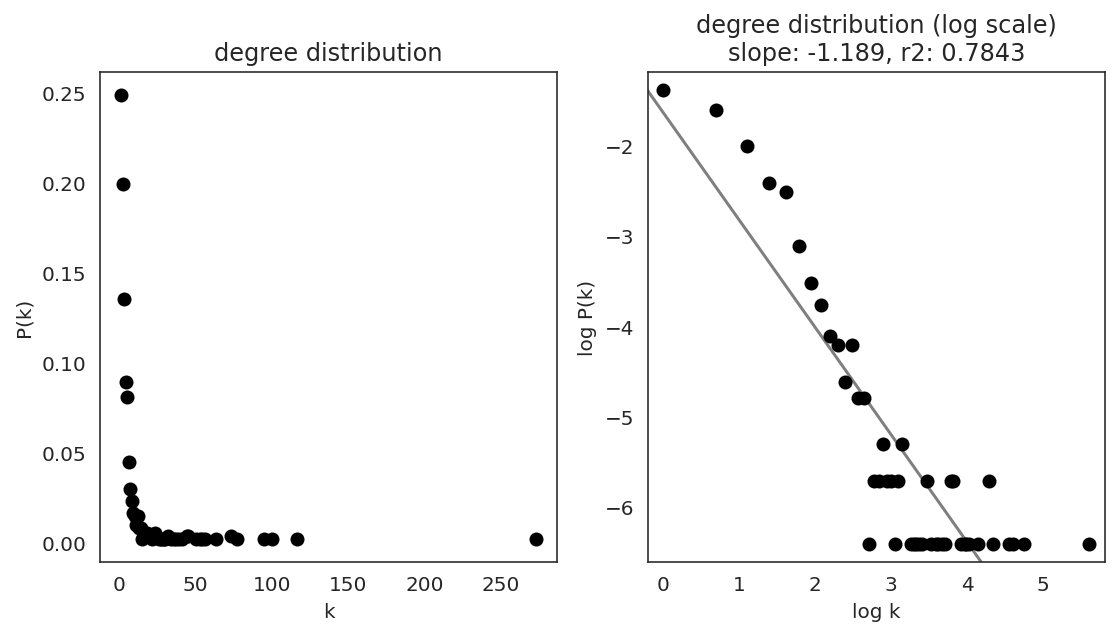
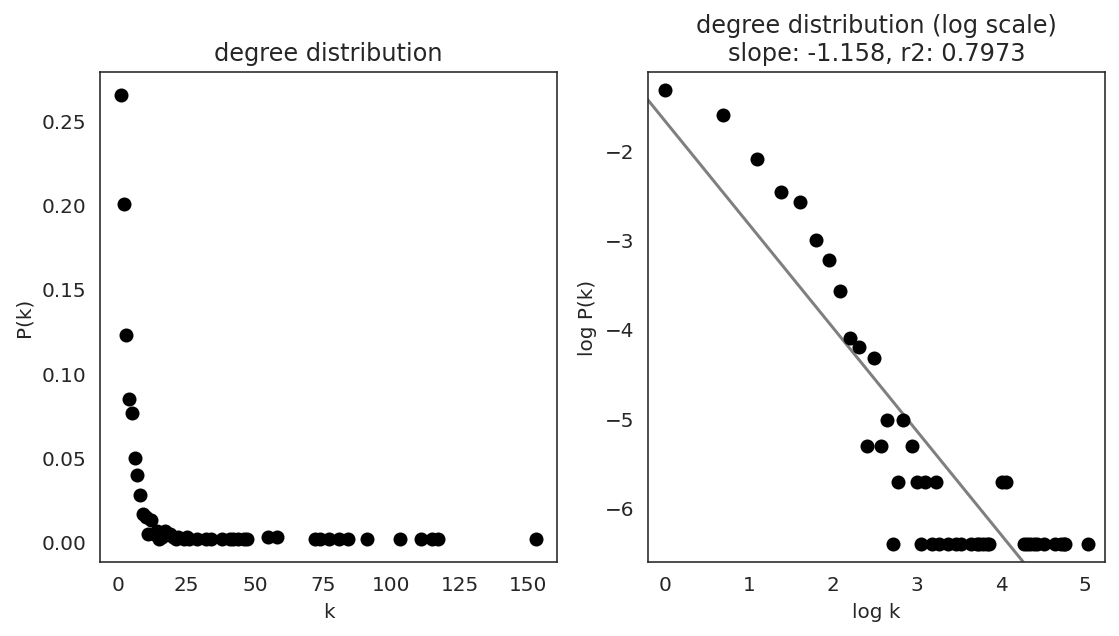
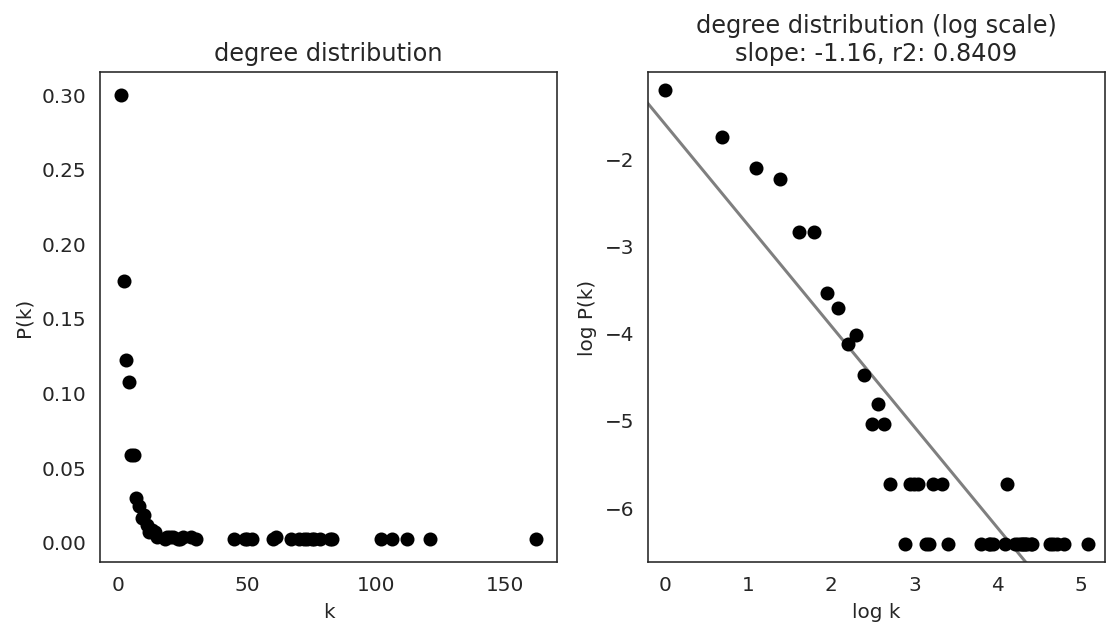
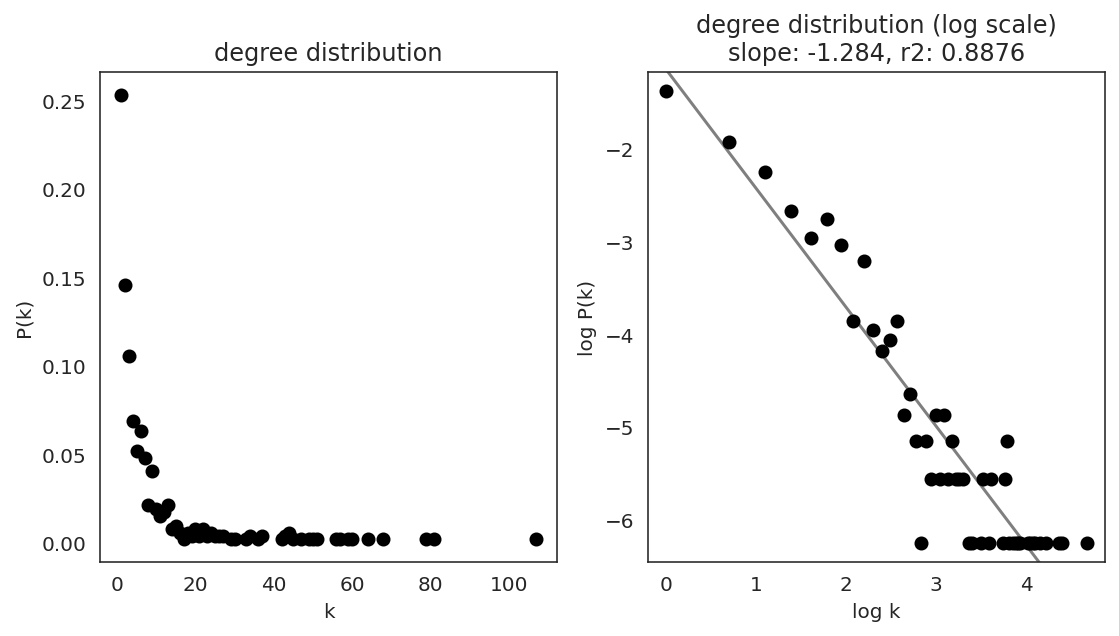
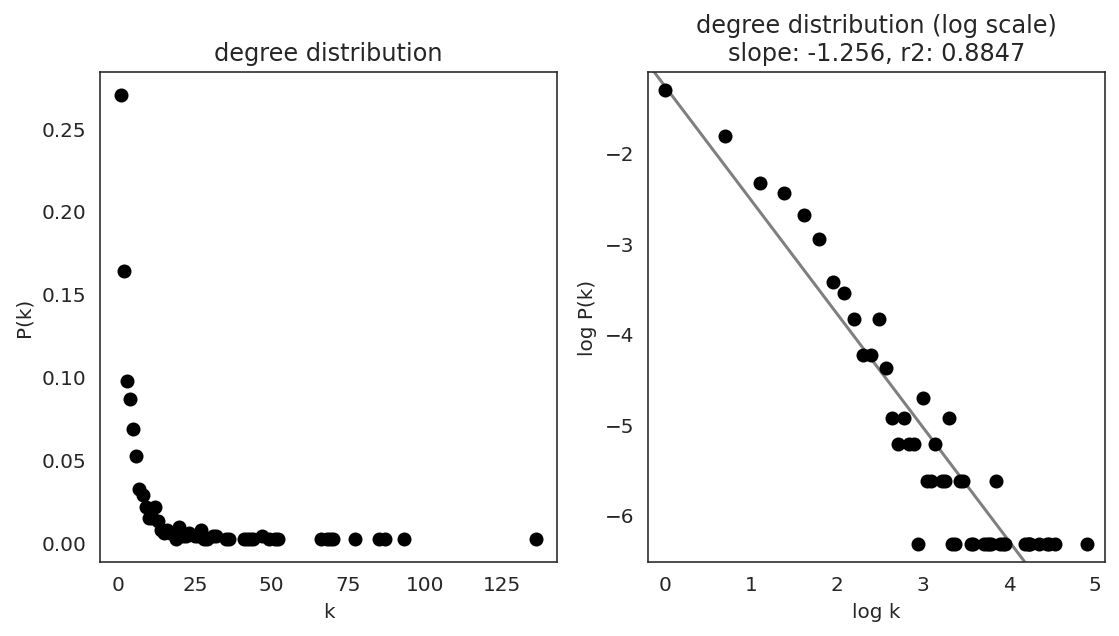
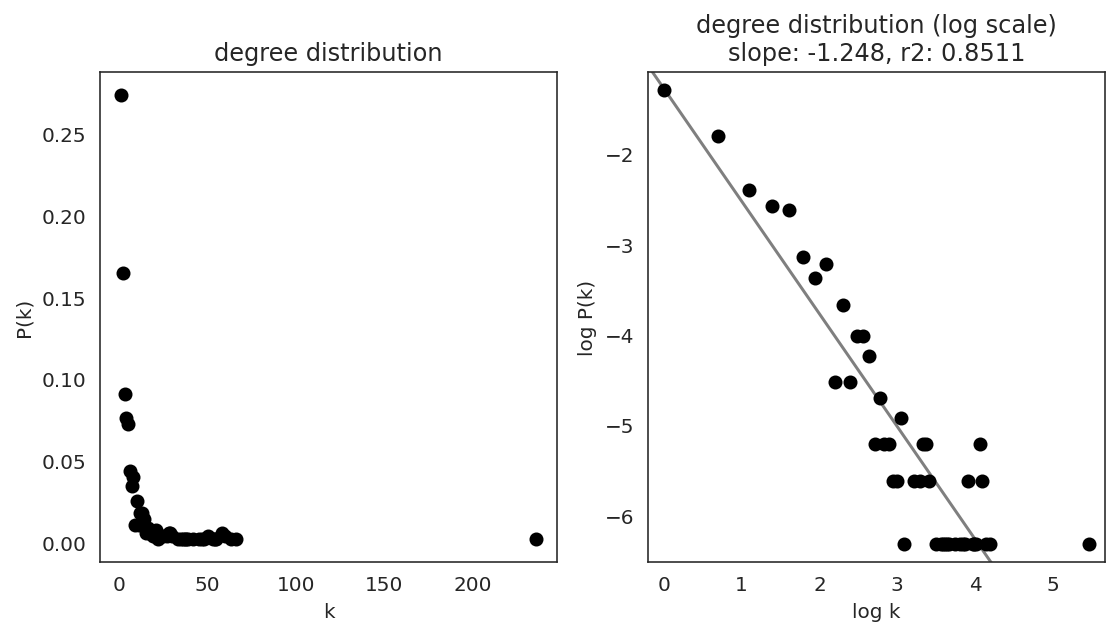
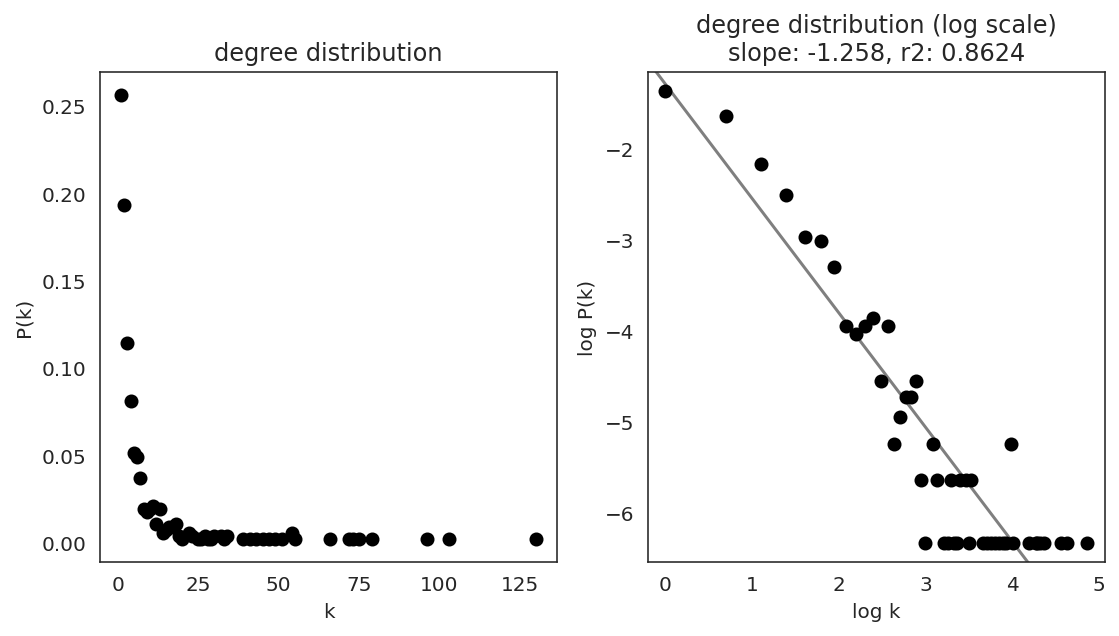
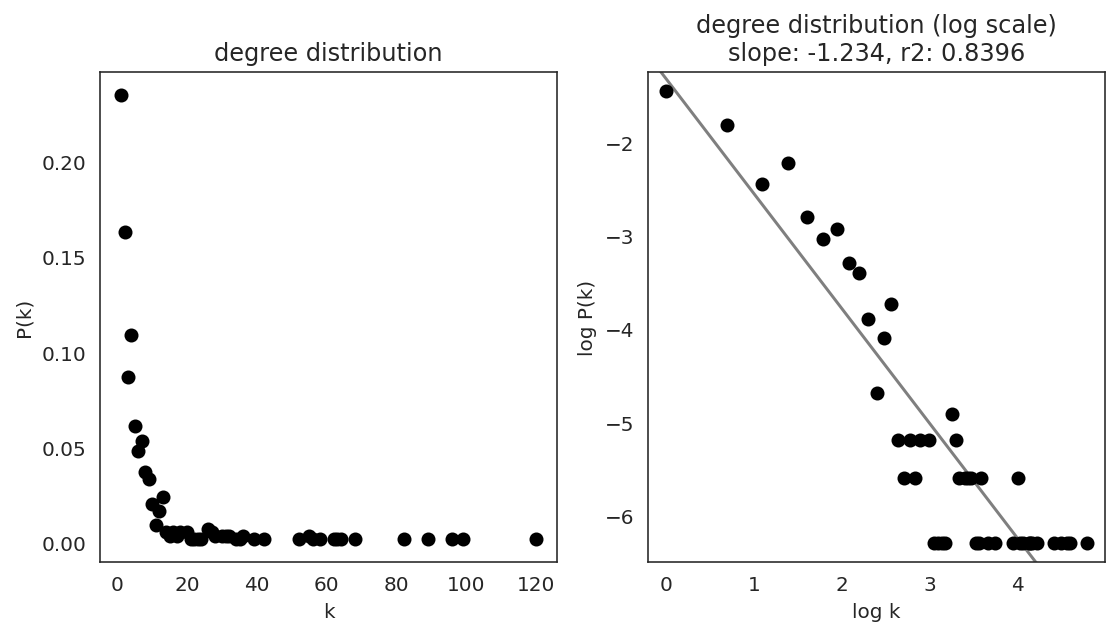
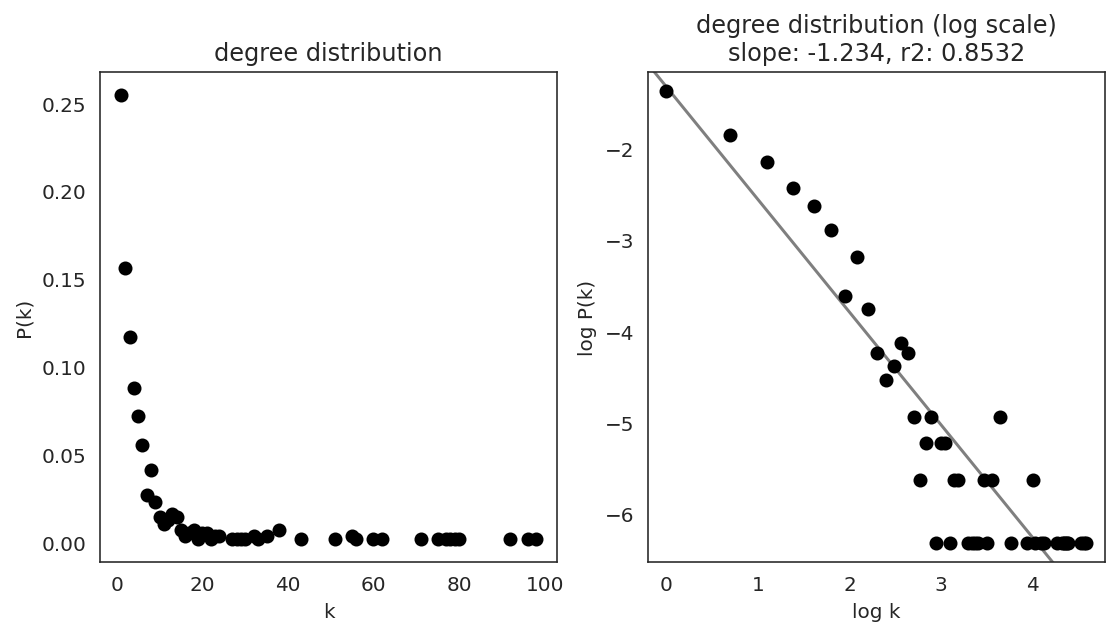
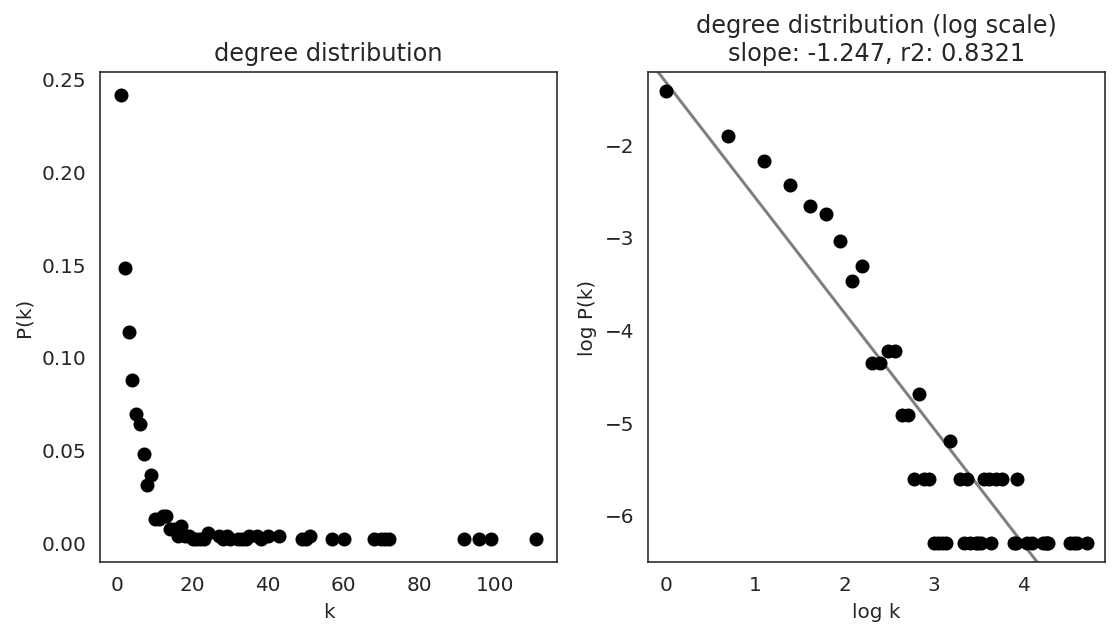
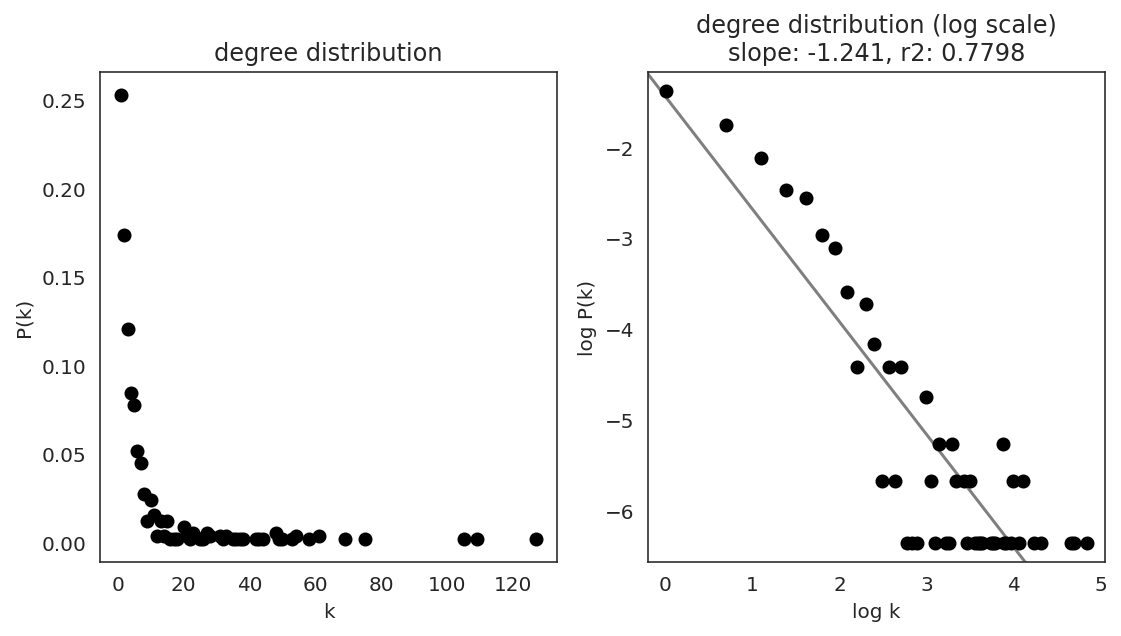
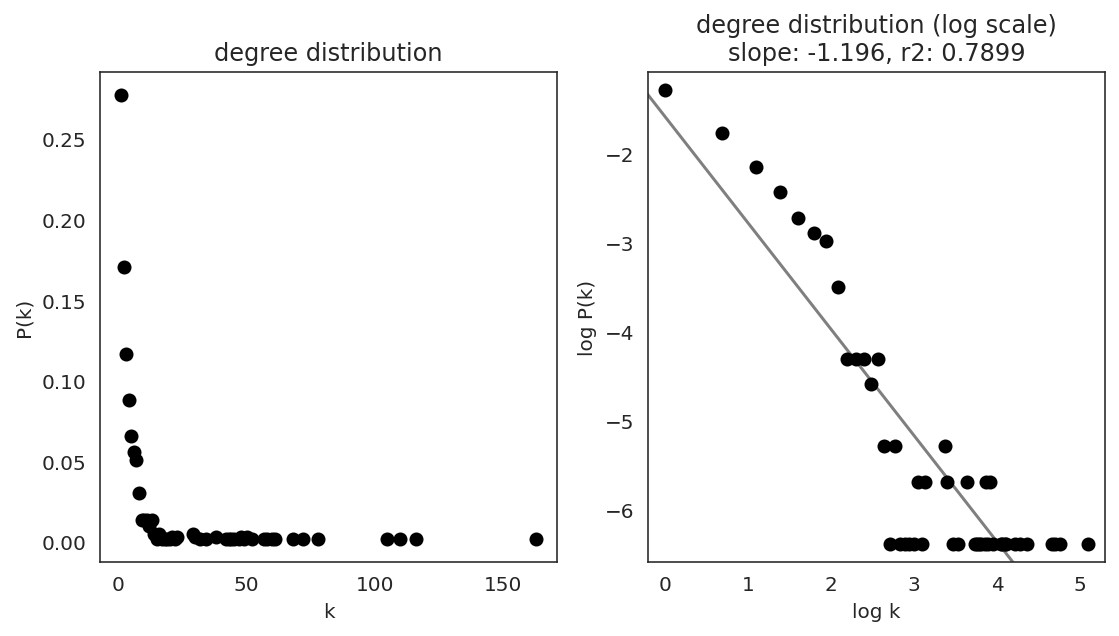
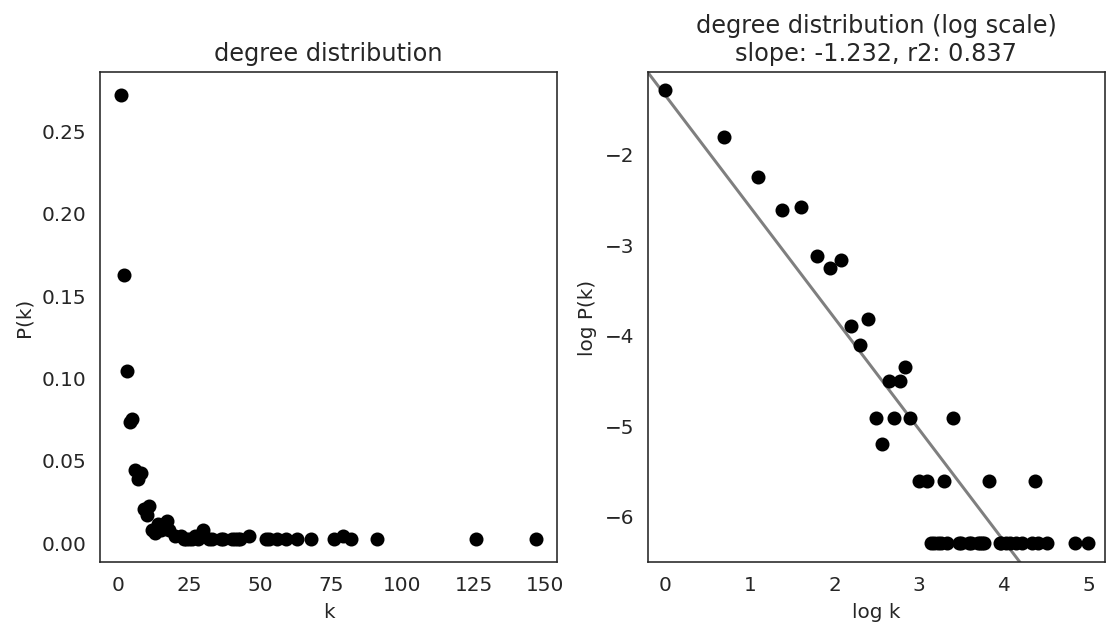
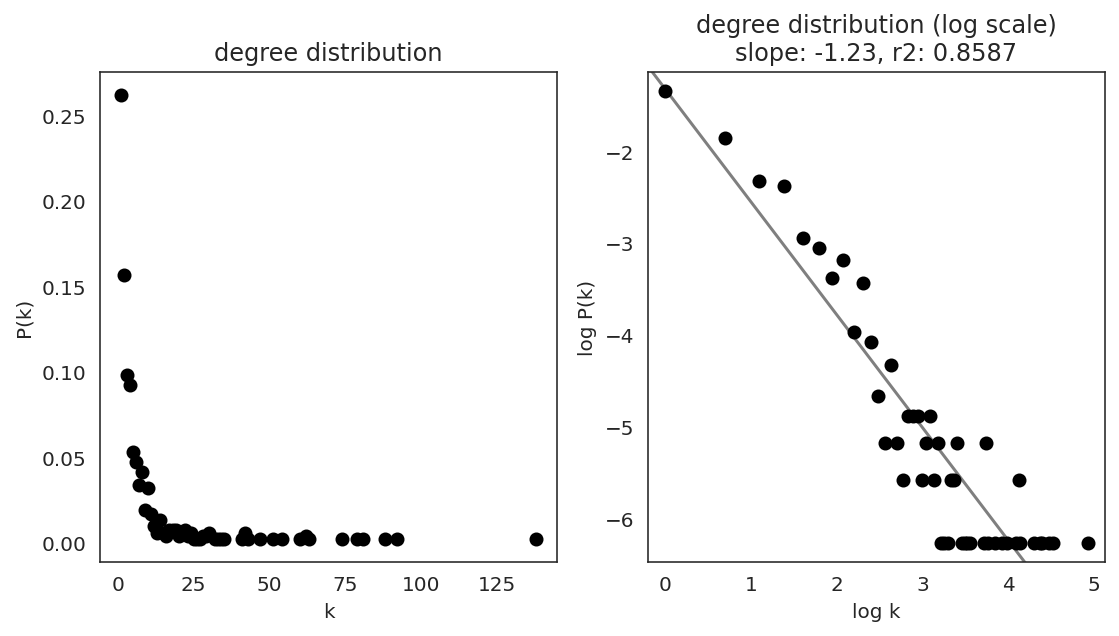
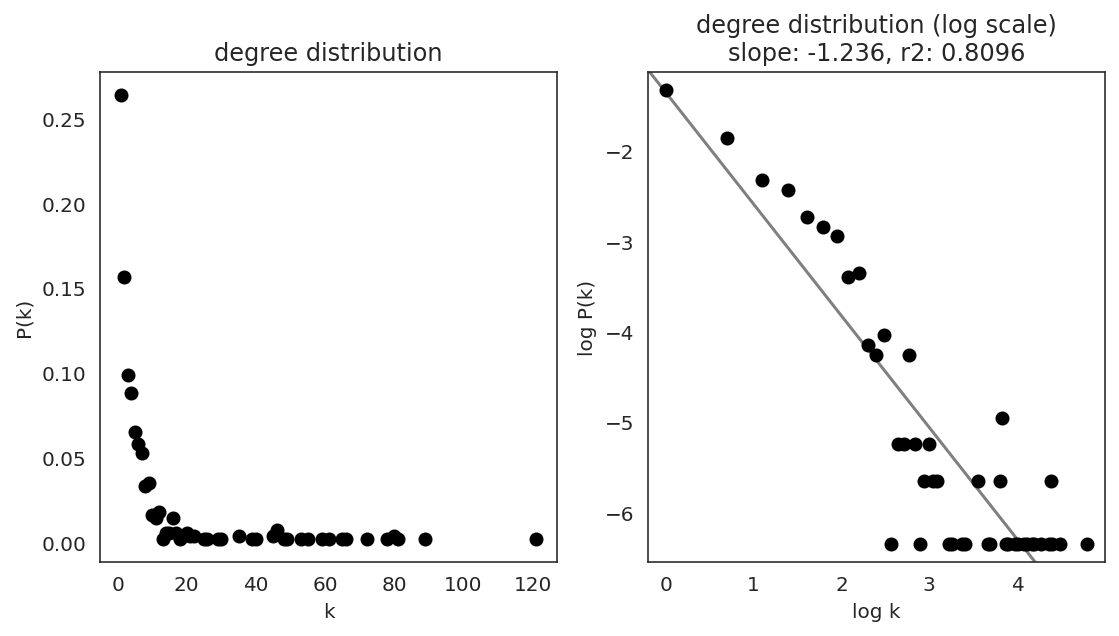
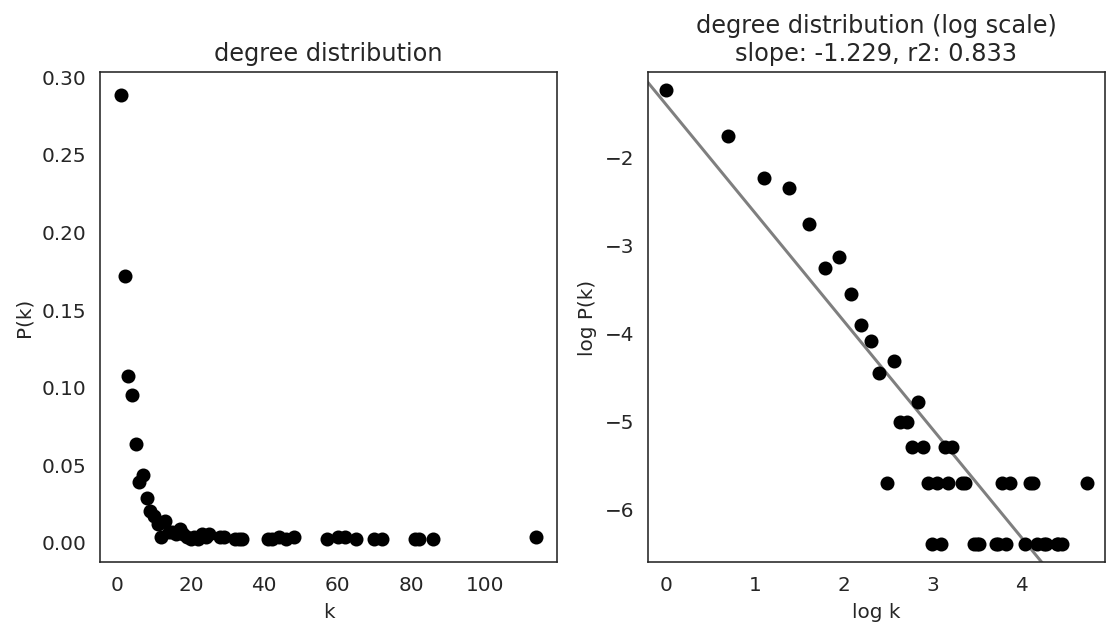
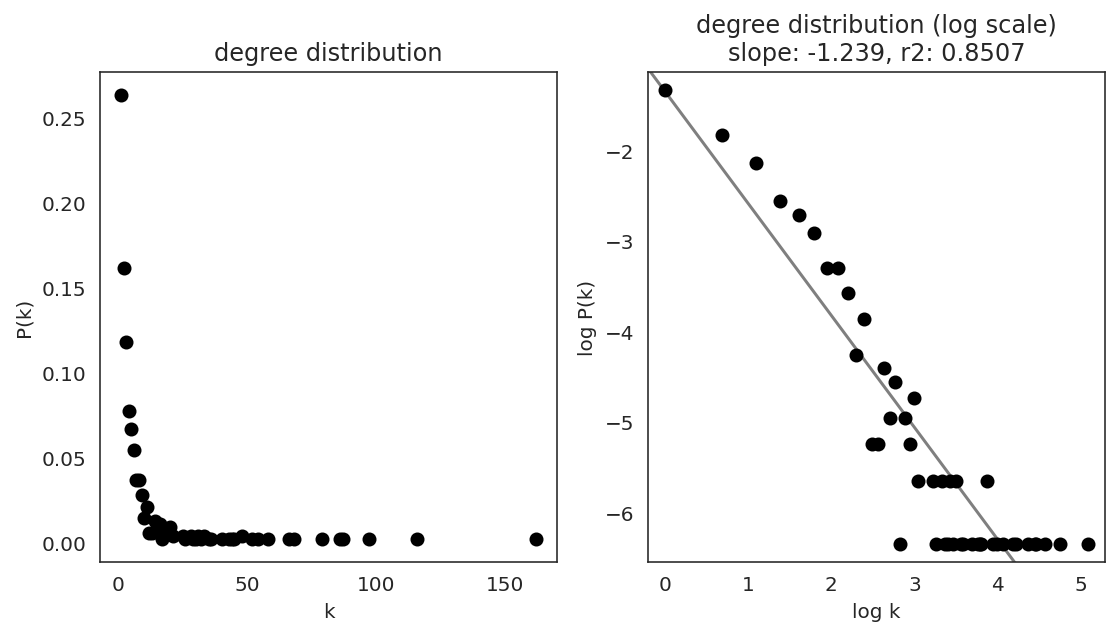
In the first step, we examine the network degree distribution.
Network degree, which is the number of edges for each node, is one of the important metrics used to investigate the network structure (https://en.wikipedia.org/wiki/Degree_distribution).
Please keep in mind that the degree distribution may change depending on the filtering threshold.
[34]:
plt.rcParams["figure.figsize"] = [9, 4.5]
[35]:
links.plot_degree_distributions(plot_model=True,
#save=f"{save_folder}/degree_distribution/",
)
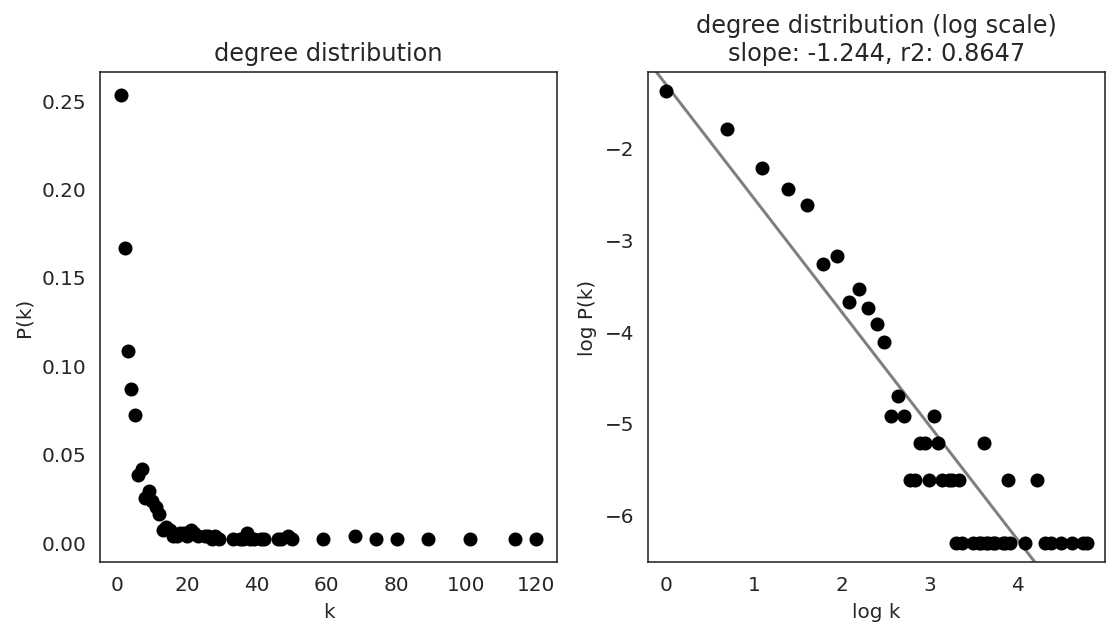
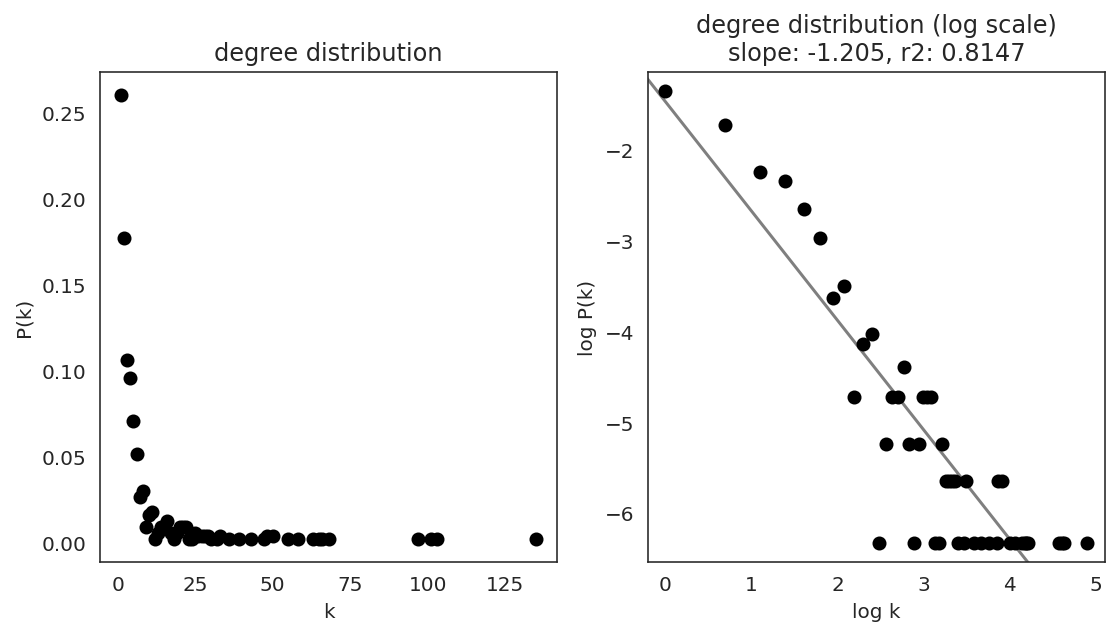
[36]:
plt.rcParams["figure.figsize"] = [6, 4.5]
Next, we calculate several network scores.
Although previous version of celloracle, links.get_score() required R packages for the netowrk score calculation, the function was replaced with new function, links.get_network_scores(), which does NOT require any R package. This new function can be available with celloracle >= 0.10.0.
The old function, links.get_score() is still available, but it will be removed in the future version.
[37]:
# Calculate network scores.
links.get_network_score()
The score is stored as a attribute merged_score.
[38]:
links.merged_score.head()
[38]:
| degree_all | degree_centrality_all | degree_in | degree_centrality_in | degree_out | degree_centrality_out | betweenness_centrality | eigenvector_centrality | cluster | |
|---|---|---|---|---|---|---|---|---|---|
| 0610010K14Rik | 3 | 0.005435 | 3 | 0.005435 | 0 | 0.0 | 0.0 | 0.026116 | Ery_0 |
| 1300001I01Rik | 2 | 0.003623 | 2 | 0.003623 | 0 | 0.0 | 0.0 | 0.054690 | Ery_0 |
| 1500001M20Rik | 1 | 0.001812 | 1 | 0.001812 | 0 | 0.0 | 0.0 | 0.012897 | Ery_0 |
| 1500012F01Rik | 9 | 0.016304 | 9 | 0.016304 | 0 | 0.0 | 0.0 | 0.128980 | Ery_0 |
| 1700017B05Rik | 2 | 0.003623 | 2 | 0.003623 | 0 | 0.0 | 0.0 | 0.006488 | Ery_0 |
Save processed GRNs. We will use this file during the in in silico TF perturbation analysis.
[39]:
# Save Links object.
links.to_hdf5(file_path="links.celloracle.links")
[40]:
# You can load files with the following command.
links = co.load_hdf5(file_path="links.celloracle.links")
If you are not interested in network analysis you can skip the steps described below. Please go to the next step: in silico gene perturbation with GRNs
https://morris-lab.github.io/CellOracle.documentation/tutorials/simulation.html
7. Network analysis; Network score for each gene¶
The Links class has many functions to visualize network score. See the web documentation to learn more about these functions.
We have calculated several network scores using different centrality metrics. >Centrality matrics are is one of the important indicators of network structure (https://en.wikipedia.org/wiki/Centrality).
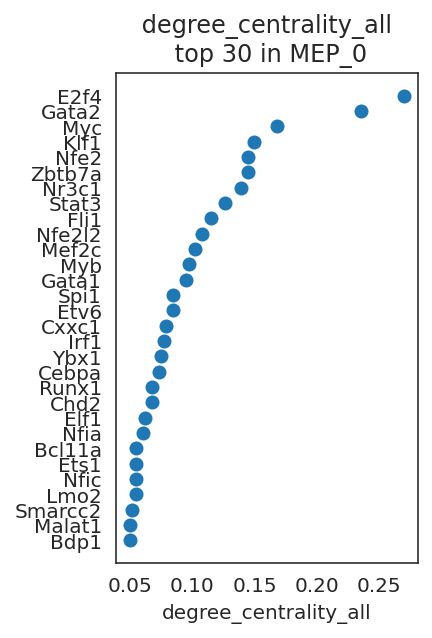
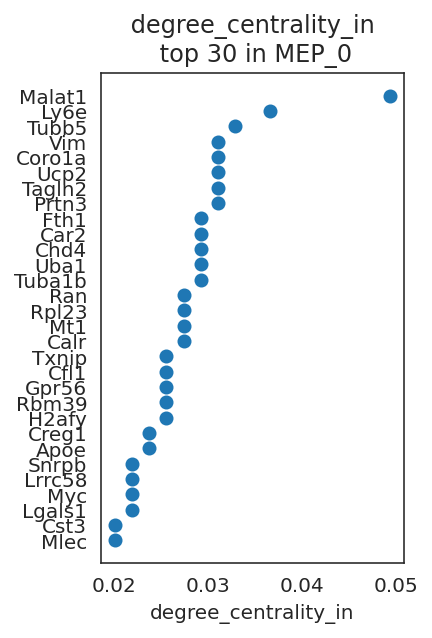
Let’s visualize genes with high network centrality.
[41]:
# Check cluster name
links.cluster
[41]:
['Ery_0',
'Ery_1',
'Ery_2',
'Ery_3',
'Ery_4',
'Ery_5',
'Ery_6',
'Ery_7',
'Ery_8',
'Ery_9',
'GMP_0',
'GMP_1',
'GMP_2',
'GMPl_0',
'GMPl_1',
'Gran_0',
'Gran_1',
'Gran_2',
'Gran_3',
'MEP_0',
'Mk_0',
'Mo_0',
'Mo_1',
'Mo_2']
[42]:
# Visualize top n-th genes with high scores.
links.plot_scores_as_rank(cluster="MEP_0", n_gene=30, save=f"{save_folder}/ranked_score")
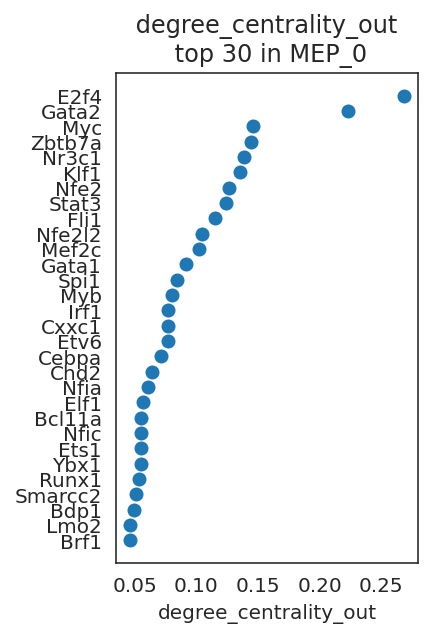
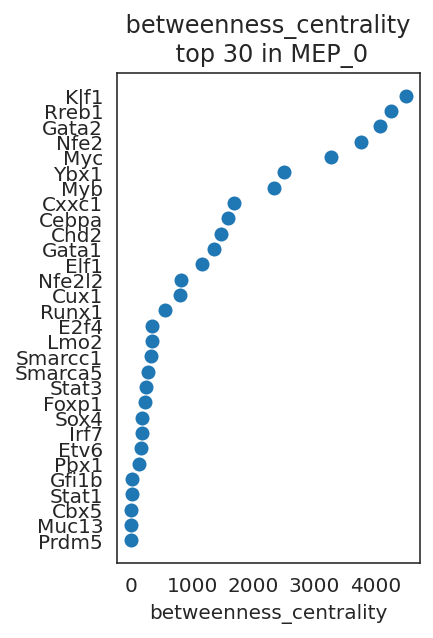
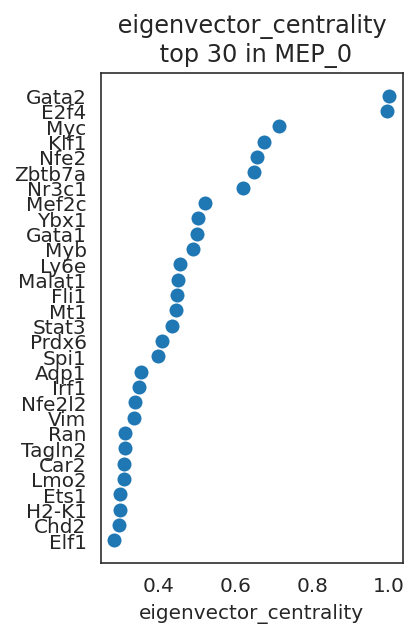
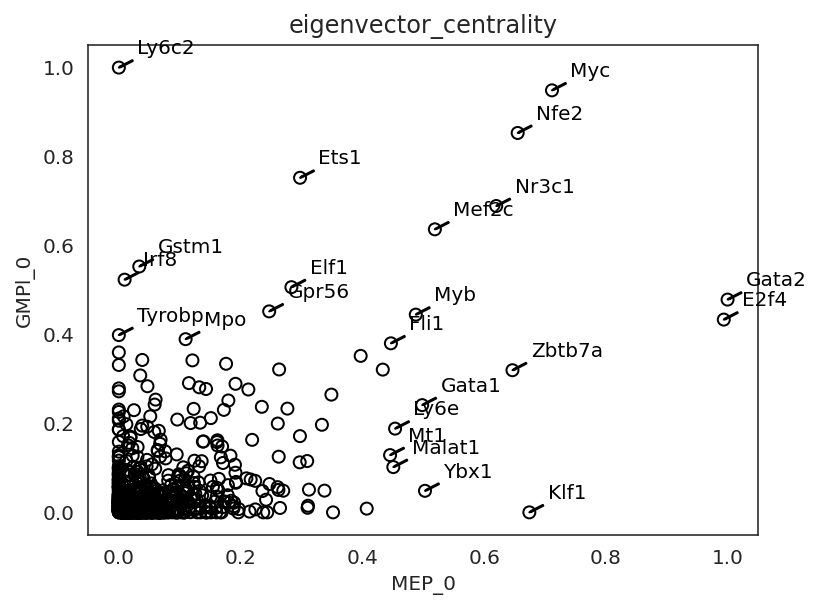
By comparing network scores between two clusters, we can analyze differences in GRN structure.
[43]:
# Compare GRN score between two clusters
links.plot_score_comparison_2D(value="eigenvector_centrality",
cluster1="MEP_0", cluster2="GMPl_0",
percentile=98,
save=f"{save_folder}/score_comparison")
[44]:
# Compare GRN score between two clusters
links.plot_score_comparison_2D(value="betweenness_centrality",
cluster1="MEP_0", cluster2="GMPl_0",
percentile=98,
save=f"{save_folder}/score_comparison")
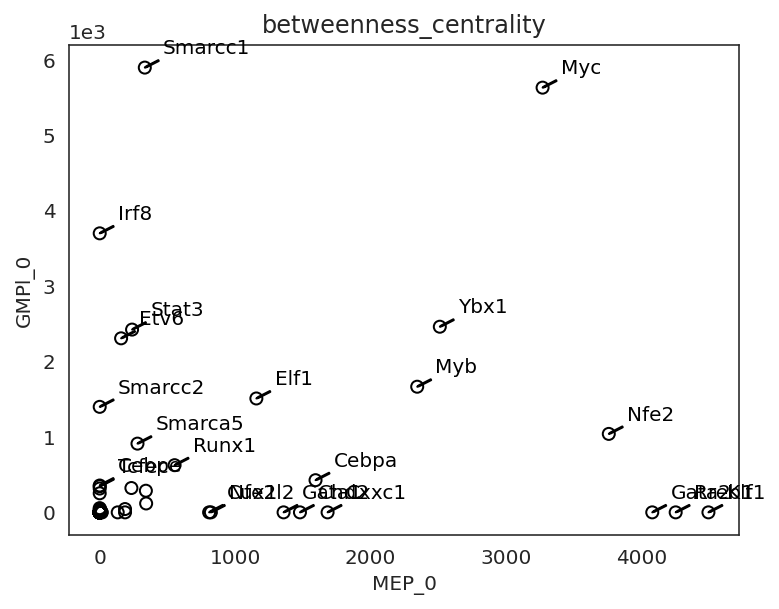
[45]:
# Compare GRN score between two clusters
links.plot_score_comparison_2D(value="degree_centrality_all",
cluster1="MEP_0", cluster2="GMPl_0",
percentile=98, save=f"{save_folder}/score_comparison")
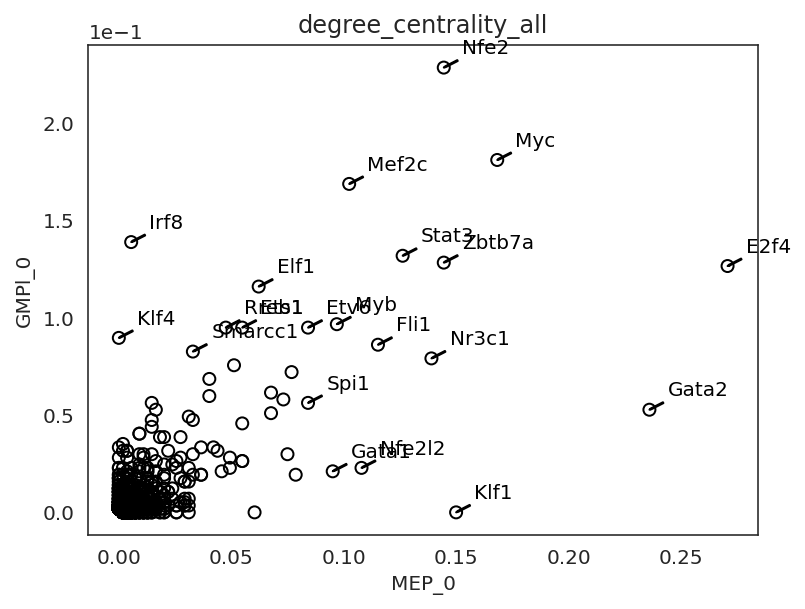
In the following section, we focus on how a gene’s network score changes during the differentiation.
We will introduce how to visualize networks scores dynamics using Gata2 as an example.
Gata2 is known to play an essential role in the early MEP and GMP populations. .
[46]:
# Visualize Gata2 network score dynamics
links.plot_score_per_cluster(goi="Gata2", save=f"{save_folder}/network_score_per_gene/")
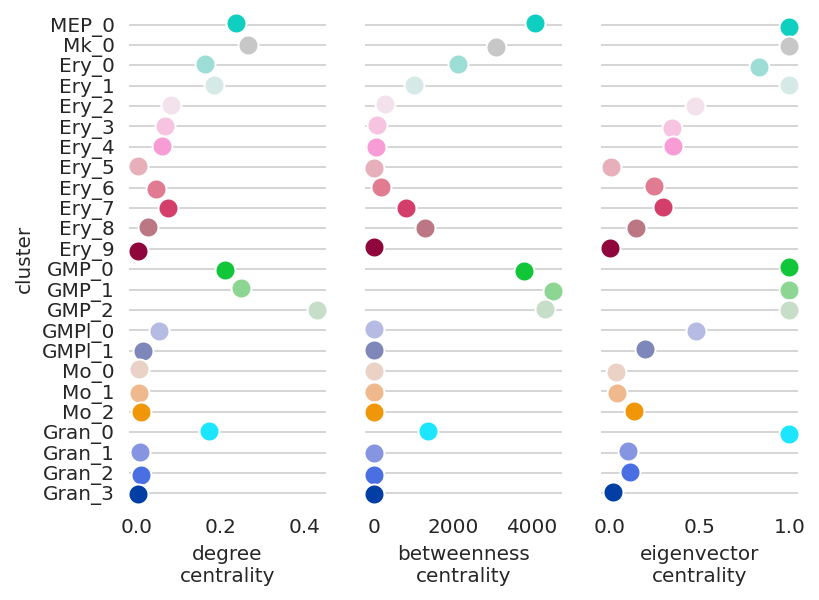
If a gene does not have network edge in a cluster, the network scores cannot be calculated and the scores will not be shown. For example, Cebpa have no network edge in the erythloids cluster GRNs. Thus these clusters do not have centrality scores in the plot below.
[47]:
# Visualize Cebpa network score dynamics
links.plot_score_per_cluster(goi="Cebpa")
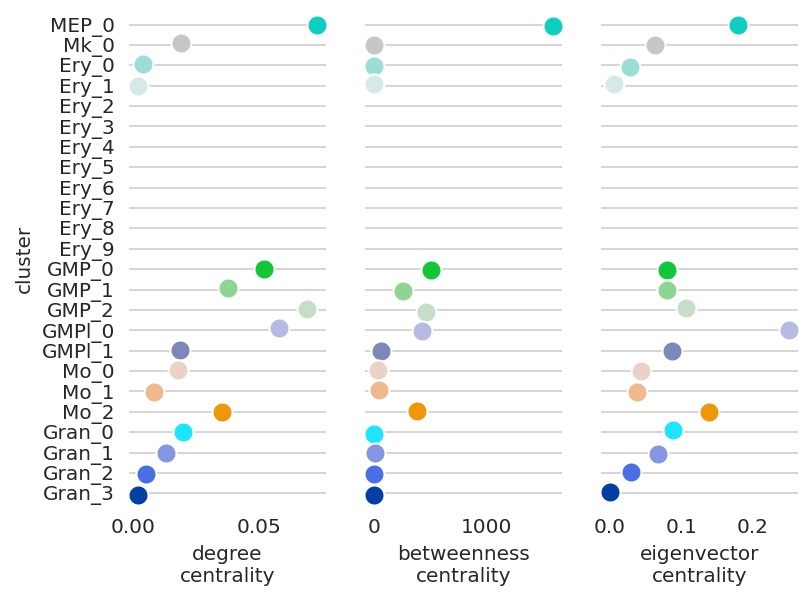
You can check the filtered network edge as follows.
[48]:
cluster_name = "Ery_1"
filtered_links_df = links.filtered_links[cluster_name]
filtered_links_df.head()
[48]:
| source | target | coef_mean | coef_abs | p | -logp | |
|---|---|---|---|---|---|---|
| 5506 | Gata2 | Apoe | 0.109033 | 0.109033 | 1.107226e-11 | 10.955764 |
| 56740 | Gata2 | Rhd | -0.096525 | 0.096525 | 4.285978e-16 | 15.367950 |
| 5519 | Nfatc3 | Apoe | -0.095612 | 0.095612 | 1.146930e-16 | 15.940463 |
| 69218 | Elf1 | Top2a | 0.093966 | 0.093966 | 3.595857e-08 | 7.444198 |
| 5550 | Zfhx3 | Apoe | 0.093560 | 0.093560 | 1.515266e-15 | 14.819511 |
You can confirm that there is no Cebpa connection in Ery_0 cluster.
[49]:
filtered_links_df[filtered_links_df.source == "Cebpa"]
[49]:
| source | target | coef_mean | coef_abs | p | -logp | |
|---|---|---|---|---|---|---|
| 45587 | Cebpa | Nrgn | 0.023446 | 0.023446 | 2.765830e-13 | 12.558175 |
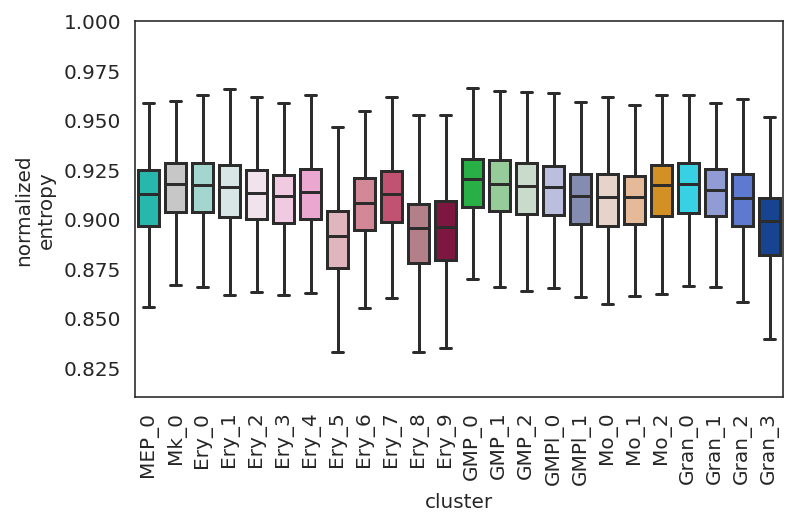
8. Network analysis; network score distribution¶
Next, we visualize the network score distributions to get insight into the global network trends.
[50]:
plt.rcParams["figure.figsize"] = [6, 4.5]
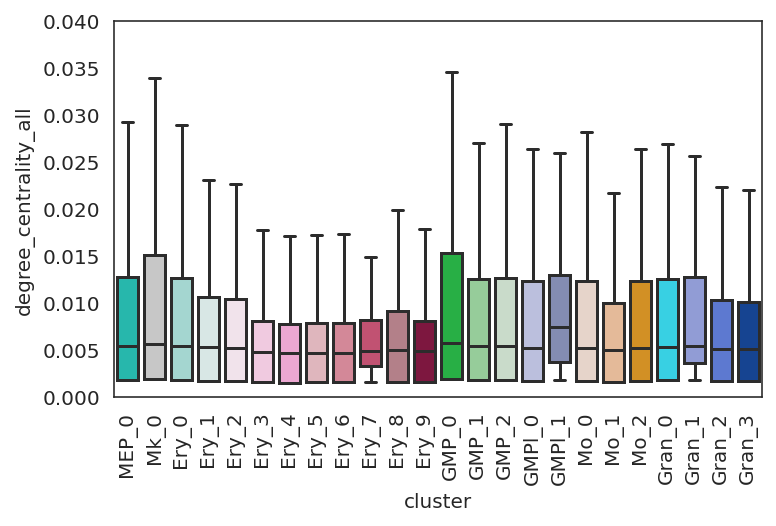
[51]:
# Plot degree_centrality
plt.subplots_adjust(left=0.15, bottom=0.3)
plt.ylim([0,0.040])
links.plot_score_discributions(values=["degree_centrality_all"],
method="boxplot",
save=f"{save_folder}",
)
[52]:
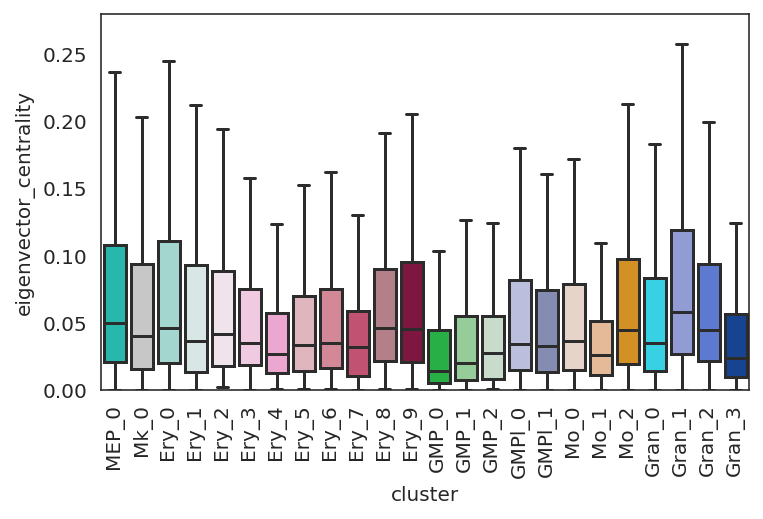
# Plot eigenvector_centrality
plt.subplots_adjust(left=0.15, bottom=0.3)
plt.ylim([0, 0.28])
links.plot_score_discributions(values=["eigenvector_centrality"],
method="boxplot",
save=f"{save_folder}")
[53]:
plt.subplots_adjust(left=0.15, bottom=0.3)
links.plot_network_entropy_distributions(save=f"{save_folder}")
Please go to the next step: in silico gene perturbation with GRNs
https://morris-lab.github.io/CellOracle.documentation/tutorials/simulation.html
[ ]: